
NEWS, EDITORIALS, REFERENCE
Object Orientation in 6502 (Take 2)

Every so often when I'm writing a new post it reminds me of something I wrote in an earlier post, so I'll go back and read it to make sure I'm covering new ground instead of just repeating myself. I wrote about "Object Orientation in 6502" in July 2017, which does not feel like a long time ago. Please, don't bother to read it.
It is not a fine example of writing, nor of clarity of thought. But, it was my first attempt at writing about Object Orientation. I've been programming object oriented code for 15 years, and I've read countless articles about OO, and even a book or two, but I've never had to take what I know from practice and put it into my own words. Writing is hard. Writing coherently and pleasingly on a technical subject is even harder. I hope this time around will be a bit better.
There is good software practice, and there is bad software practice. We all learned long ago that the GOTO command in BASIC is bad news. It leads to unmaintainable spaghetti code, and should be avoided whenever possible. Most modern languages don't even have an equivalent. When we think about the choice between programming languages, it's easy to imagine that they are mere conventions, different ways of expressing what ends up at bottom the same thing, the machine code. But abstracting in this way can hide some harsh low-level realities.
When you write in a high level language you leave a lot of the dirty work to the compiler. One of the many benefits of compilation, then, is that it enforces good practices. Code can be namespaced, functions take parameters which decreases reliance on global state, data can be typed and can only be used outside its type with explicit notation, which means it can't be misused by accident. And without a GOTO command your code can't just jump around, even though the underlying CPU probably has the equivalent of a JMP instruction.
So, essentially, high level programming languages make it easier to code well by abstracting some of the underlying details. Right? Well… it has gradually become clear to me that this is only part of the story.
A computer is a computer.
Everyone knows that CPUs get faster. In the early 80s it was 1 to 4 Mhz, in the late 80s it was 7 to 14 Mhz. The 90s saw crazy increases from 20 Mhz to hundreds, and by the mid 2000s it was GHz. Eventually we hit a clockrate plateau, but two other shiny numbers have risen along the way: The C64 was 8-bit, the Amiga was 16-bit. Later came 32-bit Macs and PCs, and now 64-bit is common across the line from workstations to smartphones. And let's not forget about cores. First you could get a PowerMac with two G4s. Separate CPUs soon turned into two cores on the same die. Two turned into 4 which soon became 6, then 8. And now you can spec out an iMac Pro with 10, 14 or 18 CPU cores. Numbers are getting bigger, more memory is available, everything's getting faster. Ergo, software can be made more sophisticated, because the raw compute resources allow for more abstract and circuitous pathways to be followed. That seems to make sense.
But this is not really accurate. It's a consumer's-magazine simplification of a much more nuanced advancement. If you only look at two, maybe three, broad statistics a large part of the story is missed.
When I was a kid, in the 80s, my VIC-20 and later my C64 and C128 meant the world to me. I thought they were the best, most interesting, most flexible computers ever. As they started to age I knew that other home computers, slightly newer, were gaining features my Commodores didn't have. But in my mind, that was just the slow march of progress, unfolding before our eyes over the course of, say, the 1980s.
In fact, that view of the world was almost completely wrong. My perspective on the history of computers was totally miopic, focused only on those few machines I'd encountered: my own, those of my friends, some machines at school. I was completely oblivious to the world of big computers, mainframes and minicomputers, that were owned and operated by governments, universities, banks and large corporations. The truth is that home computers weren't powerful or flexible (although they were interesting). They were never powerful, not even on the first day the first of a new model rolled off the assembly line. They were more powerful than a calculator, a pencil and a piece of paper, sure, but as far as computers were concerned, home computers were not powerful. They were cheap.

A Commodore 64 breadbin and a Cray 1 Supercomputer. (Not to scale.)
Minicomputers, like the PDP-11, cost $20 000 USD. The big boys cost from $3 million to $10 million, and even as the technology matured the price stayed in that range. The Cray 1, pictured above cost $7.9 million. The 6502, on the other hand, cost just $25. A complete C64 started at under $600, but within a year or two it fell to $300 then $200, then $149, and I swear I read somewhere that the final machines to roll off the production lines somewhere in Germany were only $99. The Commodore 64, like every other home computer, was not meant to be powerful, it was meant to be cheap enough that regular people could afford them. And just useful enough that those same regular people would actually be willing to part with a few hundred dollars to have one.
CPUs and Universal Computation
If a 6502 could be had for 25 bucks, then, what did all that money for a mainframe buy you? Besides memory and storage, (which are important and were also very expensive,) it turns out, you got a lot. The best analogy I can come up with is asking, what's the difference between a car and a power wheels? They both have 4 wheels, pedals, a motor, a chassis, seats and a stearing wheel. But there is a reason one is orders of magnitude more expensive than the other.
The 6502 was effectively a toy CPU. A miniature but functional model of a CPU, that mom and dad could buy for Timmy.1
Turing Completeness
Turing completeness, named after Alan Turing, is significant in that every plausible design for a computing device so far advanced can be emulated by a universal Turing machine[...]. Thus, a machine that can act as a universal Turing machine can, in principle, perform any calculation that any other programmable computer is capable of. https://en.wikipedia.org/wiki/Turing_completeness
There is, in computability theory, a universality to computation. As long as a computing device possesses the minimum necessary features for Turing Completeness, it can be used to simulate any other computing device, no matter how complex. That's a titillating idea! The problem is that this universal computational equivalence assumes an unlimited amount of memory, and doesn't stipulate the length of time required for one to fully simulate the other. But you know what they say about theory.
In theory a Turing Complete processor can be implemented with only one instruction. It's called a One Instruction Set Computer, or OISC in the flavor of CISC and RISC. No one would ever build a computer around such an architecture. It is used for teaching and learning about computation. A CPU with only one instruction is like the ultimate toy model.

https://smartsim.org.uk
To make a powerful CPU, then, why not just crank up the clockrate of a OISC CPU? Or parallelize it across a wider bus? Or give it an absurdly huge amount of memory? Clearly this is not going to work. The "power" of CPU isn't merely measured by its clock speed or the width of its busses. All things being equal, a CPU can do more in the same unit of time with more speed and wider buses, but there are practical limits on speed and memory capacity that make it impossible to scale a CPU's power using cycles per second alone. There are many properties of CPUs that contribute to their power that are difficult to understand and to explain if you're not a programmer. But, we'll try.
Some Features of the 6502
Here's what a CPU does in a very tiny nutshell. It retrieves an instruction from memory and operates on it, and then advances to the next instruction, repeat ad infinitum. Some operations instruct the CPU to treat some memory addresses as data. The data can be read in from memory, transformed in some way, including being combined with other data, and then optionally written back out to memory. The crucial element of computation is that some instructions, called branch instructions, can change the address whence to retrieve the next instruction based upon the conditional result of some previous operation.
With that said, the variation of how a CPU's instruction set can work is a world without end.
The question then becomes, what instructions are available? What do they do? How is memory loaded, how is it addressed? How much data can be loaded at once? What sorts of transformations can a datum undergo? How many conditions are there? And so on. The answers to these questions and more are different, sometimes wildly different, for every type of CPU architecture. Wars are waged, friendships are forged and shattered, arguing over what is the best way to implement these answers.2

The C64 uses a 6510, but it's an instruction set compatible variant of the 6502.
Addressing Modes
Let's start by looking at addressing modes. How does the CPU find some data to load in? The 6502 has numerous addressing modes: Implied, Immediate, Relative, Absolute, Zero Page, Indirect, Absolute Indexed, Zero Page Indexed, Indexed Indirect and Indirect Indexed. This looks complicated at first, but it's not really that complicated. You'll see.
To take an example, the CPU reads in an instruction and its the kind of instruction that needs to operate on a datum. Where does the datum come from? If the instruction operates on some state that is already present inside the CPU, and doesn't need to get any extra data from memory, then we say that that instruction uses implied addressing. That's pretty basic.
Another example then. The CPU reads in an instruction and it has the CPU read a byte of data from the memory address that immediately follows the address whence the instruction itself was loaded. We call this addressing mode "Immediate," for obvious reasons. A little more complicated but not much more.
Let's step it up. An instruction is read in, it tells the CPU to read in the next two bytes immediately following, but those bytes are not the data to be operated on. They are an address whence to load a third byte, which is to be the instruction's datum. This is called "absolute" addressing. The bytes following the instruction aren't the data, they point at the data. A form of indirection, but a limited form, because the pointer itself (generally speaking) is a fixed or absolute value.
Now let's crank it up to 11. An instruction tells the CPU to read in a byte. But that byte's not data, it's an address. But that address doesn't hold a byte of data, it holds… an address. And the data is then read out of that location. This mode, doubly-indirect, we call indirect indexed. The "indexed" part is an added complication that we'll return to.
There are variations on these addressing modes, but this brief overview shows the 6502's general scope of flexibility for addressing. Now think about this compared to the theoretical OISC architecture, which doesn't have any of these addressing modes, and yet can still—through some insane circuitous contortions—simulate anything these addressing modes can accomplish. But it can't do that very efficiently. These addressing modes are cool, but what if a more sophisticated architecture had 10x as many addressing modes? Addressing modes that were more convoluted, like two dimensionally indexed, or combining a relative offset to an indexed table, and on and on.
Just like the OISC can inefficiently contort its way into the 6502's ready native addressing modes, so too the 6502 can probably contort its way into simulating most other more complex addressing modes. But they won't be fast, and they won't be pretty. We'll see in a bit how this matters in practice.
Registers
The 6502 has 3 general registers. The accumulator, and two index registers, X and Y. Each just 8 bits wide. Registers are temporary memory locations within the CPU. There are instructions to copy data from memory into the registers and from the registers into memory. There are instructions for copying the contents of one register into another.
With the 6502, the only way to move data from one place in memory to another is to explicitly pass it through one of the registers. For example, load A from one location, store A to a different location. And if you have to move a block of memory, the only way to do it is one byte at a time.
A register is more than just a temporary holding place. The contents of the different registers are implicitly used as the operands of various other instructions. How exactly each can be used, though, is very constrained. For example, there are absolute mode versions for loading all three registers. Any register, A, X or Y, can be loaded directly from the contents of any absolute memory address. Very simple, very clean. But what about if you want to use one of the more sophisticated addressing modes? Absolute Indexed is a mode we haven't talked about yet. The data is loaded from an address that is composed in realtime by adding the value of one of the index registers to the absolute address. That's very cool, and it's useful in many situations.
But only X and Y can be used as the "index", (which is why they're called index registers.) If you want to load the accumulator, then either X or Y may be used as the index. But if you want to load into Y, then only X can be used as the index. And if you want to load X, then, naturally, only Y can be used as the index. It is impossible to load X or Y using either themselves or the accumulator as the index. That's just a restriction you have to live with.
It gets much more restrictive though. Remember that "cranked up to 11" indirect-indexed mode? It's even more constrained. First, the address of the pointer to be indexed must be in zero page. On a C64 that means the pointer must be somewhere within the first less-than-half-a-percent of all the memory available. And if it ain't there to start with, you have to copy it there first. Next, only the Y register can be used as the index, and the accumulator is the only register you can load into. It's an incredible mode, that can be used for doing some very fancy footwork, as we'll see soon enough. But at the same time, it can only be used in a very particular way. It is surely easy to imagine other CPU architectures that have similarly—or more—sophisticated addressing modes, but without any of the constraints.
It isn't only the fancy-footwork addressing modes that have tight constraints though. On the 6502 even the simplest, implied mode, instructions have limitations you wouldn't expect. For example, INX, INY, DEX and DEY are used to increment and decrement by one the X and Y registers respectively. But there is no way to similarly increment or decrement the accumulator, despite how often that would be useful. On the flip side, the accumulator can do things X and Y can't. The most obvious, again in implied mode, is pushing to and pulling from the stack. Only the accumulator can be directly pushed to the stack. Anything else you want on the stack has to pass through the accumulator.3 I mentioned earlier that the contents of one register can be copied to another, these are implied mode addressing as well, but X and Y can only be exchanged with the accumulator. There is no way to copy X directly into Y or vice versa, without passing through A, or writing out to memory and reading back in.
Or how about arithmetic? The 6502 supports 8-bit addition and subtraction (with carry), as well as a handful of arithmetic-like operations, logical AND, OR and EOR, and shifting and rolling bits left or right. These operations can only be applied to the accumulator, or directly to memory referenced via a restricted set of addressing modes. But you cannot roll the X register for example. You cannot perform an EOR bitwise operation on the Y register, and so on. You cannot add X to Y or Y to X, nor can you add X or Y to A. The CPU has an add instruction, but you can only add something from memory to the accumulator. Period.
Once again, it is very easy to picture a more advanced CPU that has none of these restrictions. The PDP-11 minicomputer, for example, which was announced by DEC in 1970, has eight 16-bit general purpose registers that can be used far more flexibly in all kinds of crazy addressing modes. Many of the things it can do in a single step require several instructions, juggling data around, to pull off on the 6502.
Jumps and Branches
Jumping (and saving the return address) is very important. It allows for modularization and reusability of code. It also enables recursion, which can be a very powerful algorithmic tool. But as far as computation theory is concerned, conditional branching is even more fundamental. Conditional branching is one of the key ingredients that makes a computer a computer. Branching allows for the implementation of if-then flow control, which in turn enables loops and other higher level flow control mechanisms.
There isn't much to say about branching, other than that the 6502 uses only a single signed byte for the branch argument. And branches are the only instructions that use the relative addressing mode. Therefore a branch can be either forward or backwards, relative to where the execution address currently is, but it can only move up to ~127 bytes in either direction.
Jumping is a bit more complex, so let's talk about this to some depth. The 6502 has two types of jump instruction, JMP and JSR. A JMP is the equivalent of GOTO in BASIC, while JSR is like GOSUB. Although JMP can easily be misused to produce spaghetti code, it is sometimes necessary. (To implement a long branch, for example.) But how exactly does a JMP work? Remember that the accumulator, and X and Y are general purpose registers, (although they have some specialized uses.) There are other registers in the 6502 that are special purpose, one of which is the program counter.
Of all the registers, only the program counter is 16-bit, which it has to be to supply the value for the 16-bit address bus. Whenever the CPU is reading or writing data, it is reading from or writing to whatever address is set on the address bus. It is usually the program counter that provides this address. The program counter automatically increments as part of the implicit behavior of most instructions. This is the mechanism by which the CPU "gets the next byte" or "proceeds to the next instruction."
For example, let's say the program counter is currently $0900. The CPU reads an instruction from that address, and let's say it's an $A9. That's the instruction for immediate mode LDA. This instruction takes one argument and puts it directly into the accumulator. To accomplish this, the instruction automatically increments the program counter changing the value on the address bus to $0901. The CPU reads another byte off the data bus and puts it in the accumulator. Then the program counter gets incremented again to $0902, ready for the CPU to read the next instruction off the data bus.
Now let's take the JMP instruction. It comes in two addressing modes, Absolute and Indirect. Just as an absolute LDA loads the next two bytes into a temporary space, so does the absolute JMP. After loading in the two bytes, however, JMP just copies them into the program counter register itself. Bingo bango, the CPU then proceeds to the next instruction by reading from the "next address" which is whatever value is now in the program counter.
If LDA loads a byte into the accumulator, and LDX and LDY load a byte into the X and Y registers respectively, then we can think of JMP as more or less an "LPC"… Load the Program Counter. That is cool. The elegance and simplicity—once you see how it works—just puts a smile on my face.
Once we know how an absolute JMP works, and we know how an indirect LDA works, it is easy to understand how an indirect JMP would work too. It loads in the two bytes following the instruction, but rather than use them directly as the address to set the program counter to, they are temporarily used as an address whence to read two more bytes. Then those bytes are put into the program counter, and execution continues from there. So that's cool.
But most of the time a program will be calling JSR rather than JMP. Once you know how JMP works, how JSR works is also head-smackingly simple. Before executing the JSR, the current value of the program counter is pushed to the stack. Then everything else proceeds as it did for JMP. When the CPU executes an RTS instruction (to return, to continue execution following the JSR), the two bytes are pulled off the stack and used to set the program counter again. 4
So, what's the problem? Wow, this all sounds great!
The problem is that of all those ten addressing modes mentioned earlier, JMP only supports two addressing modes, Absolute and Indirect, and without support for any form of indexing. And JSR, which is far more common, is available in only a single addressing mode… Absolute. The restrictions are almost unbelievable.
By now you probably get the point. In other CPU architectures the equivalent of JMP and JSR might be available in a multitude of flexible addressing modes. Whereas, on the 6502, if you want to JSR through something dynamic, you would have to use other instructions to read the target address and write it into the bytes immediately following the JSR instruction. 5 An alternative, if you want an indirect JSR, is to JSR to an indirect JMP.
Either of these options has consequences that will become more obvious when we discuss object oriented code on the 6502, below.
Structuring Object Oriented Code on the 6502
It may seem like we took a long detour to talk about specific features and limitations of the 6502 before finally coming back to the main point of this post. But it is necessary to understand how the CPU works before we can see how it might be used to execute object oriented code. We looked at the 6502's addressing modes, registers and jumps and branches. All of which are relevant to the discussion below.
About Object Oriented Code
In my previous post on Object Orientation on the 6502, I gave a rather shallow and difficult to follow description of the theoretical principles. I'd rather not repeat that misadventure. Instead, I'll stick to what we're actually trying to accomplish, and leave as an exercise to the reader to lookup any terminology they are unfamiliar with. Also, many of the things I stated in that earlier post are just wrong, and I hadn't fully thought out how to structure the code. Heck, I probably still haven't got it all sorted out.
(Object Orientation and Object Oriented Code shall often be shortened to OO and OOC for brevity.)
In OOC there are two main "entities" that we need to discuss. There are classes and objects. Usually an object is described as an instance of a class. But this doesn't capture how these entities exist in memory, or how they are implemented. In my first post on OO I really didn't have it straight in my head how this was supposed to work.
First, how the code is physically broken down. Supporting system routines are found in the Toolkit module, which is structured like each of the other (non-object-oriented) system modules. All of the other toolkit code is in a separate sub-folder, so the many toolkit files are collected together and not simply scattered amongst the rest of the system files. The reason this is necessary is because each class, as is standard practice, gets its own suite of files. The suite consists of:
- object header (//os/tk/s/:tkview.s)
- class header (//os/tk/h/:tkview.h)
- class implementation (//os/tk/:tkview.a)
A class is essentially a set of routines that are designed to operate on an object of a certain type. An object is essentially a structure of properties, which conforms precisely to the object header, and belongs to and identifies itself with a class.
It's important to have a clear idea of the difference. The set of routines that define the behavior of a class are stored once, at one place in memory, as part of system code, somewhere physically near (just below) the Toolkit system module. An object, on the other hand, initially has no representation in memory. The system ships with the object header file which can be included by application or utility source code. The object header file consists of a list of labels, which define property names and their offsets from a base address. The object header also defines the size of the object, which is the sum of the sizes of all its properties.
There can be many copies of an object, as many as the application needs. An object is created, essentially, by allocating a block of memory of the size of the object. The newly allocated block of memory is just a generic block of allocated memory, it needs some initialization for it to come to life as an object that belongs to a class.
Note: We should take a moment here to note that the object oriented toolkit takes dynamic memory allocation for granted. There is a reason memory allocation is one of the low-level services C64 OS provides.
Class ↔ Object Relationship
There are some critically important links between classes and objects that make them work.
The class header file consists of a list of labels, which define the names of routines and specify their offsets in a jump table which begins at the base address of the implementation of the class. Class routines are designed to operate on an object currently in focus, and are called methods. A class's implementation may have more routines than the ones made public via the jump table. The jump table defines the class's interface with other classes and application code.
Just prior to a class's jump table, there are two 16-bit words. The first is a pointer to this class's super class. The super class pointer points to the place in memory where another class implementation begins, with its own super class pointer and jump table, etc. These super class pointers are what link classes together in an inheritance hierarchy. More on that soon. The root class is the class from which all other classes descend, and it is identified by having a null ($0000) super class pointer.
The second 16-bit property, immediately following the super class pointer, is the size of this class's object. This is NOT the size of the class definition, it is the size of the object structure that must be dynamically allocated to instantiate the class as a new object.
The root class, in C64 OS's toolkit, is called tkobj. Short for, Toolkit Object. The class header for tkobj defines two methods, and the object header defines just one property. The property is called ISA, which stands for "is a", and is a 16-bit pointer to the class implementation that this object belongs to. So, every toolkit object has, at its center, the ISA pointer. And in fact ISA is the only property necessary for a block of allocated memory to be an object.
The two methods are init and delete. Tkobj's implementation of init is an abstract placeholder. It doesn't actually do anything, but is there to be implemented by subclasses. The init method does not set the ISA pointer, this is done elsewhere, which we'll get to. That is because, calling a method before the ISA pointer is set isn't possible. The delete method does only one thing. It unallocates the memory previously allocated for the object.
Okay. Now, how do we create a new object?
We have to remember that an application written for version 1.0 of C64 OS needs to remain compatible with version 1.1, and 1.2, etc. We ran into this problem of how an application should find the system routines, at runtime, when the sizes of modules and their offering of routines is changing from OS version to OS version. We now have a similar problem of how application code should find class implementations.
Aside: Some people have pointed out to me that dynamic linking of shared objects is a problem that was solved a long time ago. So, why am I reinventing this wheel? On big boy computers shared objects contain a standardized symbol table. Offsets into the library are listed alongside a human readable text label and data type code. The application, then, must also include the symbol names that it needs to access externally. At runtime the symbol offsets are looked up, by string comparison, and their addresses are substituted in.
By the standards of the C64, this system is insanely inefficient. The unix command line tool "nm" can be used to list a shared object's symbol table. I used it to checkout LibXML2.2 on macOS. This one solitary library is 2.2 megabytes of code. Its symbol table holds 3071 entries, and the string labels alone total to more than 65 kilobytes of data. While these sorts of extravagances are acceptable on a computer with memory measured in the range of hundreds of megabytes to tens of gigabytes, it is not acceptable on a computer with a total addressable memory of just 64K. That is why I am reinventing this wheel. It's also been fun to solve old problems in news ways.
I discussed in last month's post, File-Based Clipboard, how C64 OS implements the equivalent of mimetypes. Mimetypes are typically human readable strings of text. It's very inefficient to deal with these on the C64, because memory is unbelievably precious. Instead there is a datatypes header file, included with the OS, against which applications can be assembled, that lists labels to single byte integers. One byte for type, provides for up to 256 possible base datatypes. Each of these can then have one byte for subtype. For a possible maximum of (256*256 = 65,536) datatypes. Far more than C64 OS applications will in practice ever support. Using text strings is simply overkill. Similarly, the toolkit provides a set of classes. Along with the header file for each class is a file called classes.h that enumerates the classes themselves. Each class, regardless of how they are hierarchically related to each other, is assigned a unique single byte identifier.
This puts a hard limit on the number of classes providable by toolkit at 256. This limit will never be reached. For one, because we'd run out of memory way before reaching that limit. And for two, even in 2012, the iPhone's UIKit (not including foundation classes), the iPhone's version of C64 OS's toolkit, had just 80 classes. Toolkit will begin its life with approximately 14 classes, maybe fewer. My original goal was for it to consist of just 6 classes. But, that was a bit sparse. I'm planning a future post to discuss the toolkit class hierarchy itself, so I won't be going into any detail on that in this post.
To instantiate a class, that is, to create a new object, you call classptr from the Toolkit module. This routine is accessed, dynamically, like any other C64 OS module routine. You pass in a class ID, which your code can do by label. Classptr is assembled with the toolkit module along side the rest of the OS modules, at the same time as the toolkit classes, and therefore knows the addresses of all the built-in classes. It returns a RegPtr (X/Y lo/hi byte) to the start of the class.
Next, you call tknew from the toolkit module, and pass it a pointer to the class. This allows you to call classptr, and then immediately follow up with a call to tknew. But it also allows you to call tknew on its own, and pass in a pointer to a custom class provided by your application. If your application implements a custom class, the custom class's super class pointer has to be pointed at whatever class from toolkit it inherits from. This can be done in the app's init routine by making up front calls to classptr.
Tknew uses the pointer to the class to access the object size property. It uses this size to make a memory allocation. It then takes the pointer to the class and writes it into the first two bytes of the object, these two bytes are the ISA pointer. Tknew returns a RegPtr to the newly created object.
You can see now how the entities are related together. So, let's take a look at this visualized.
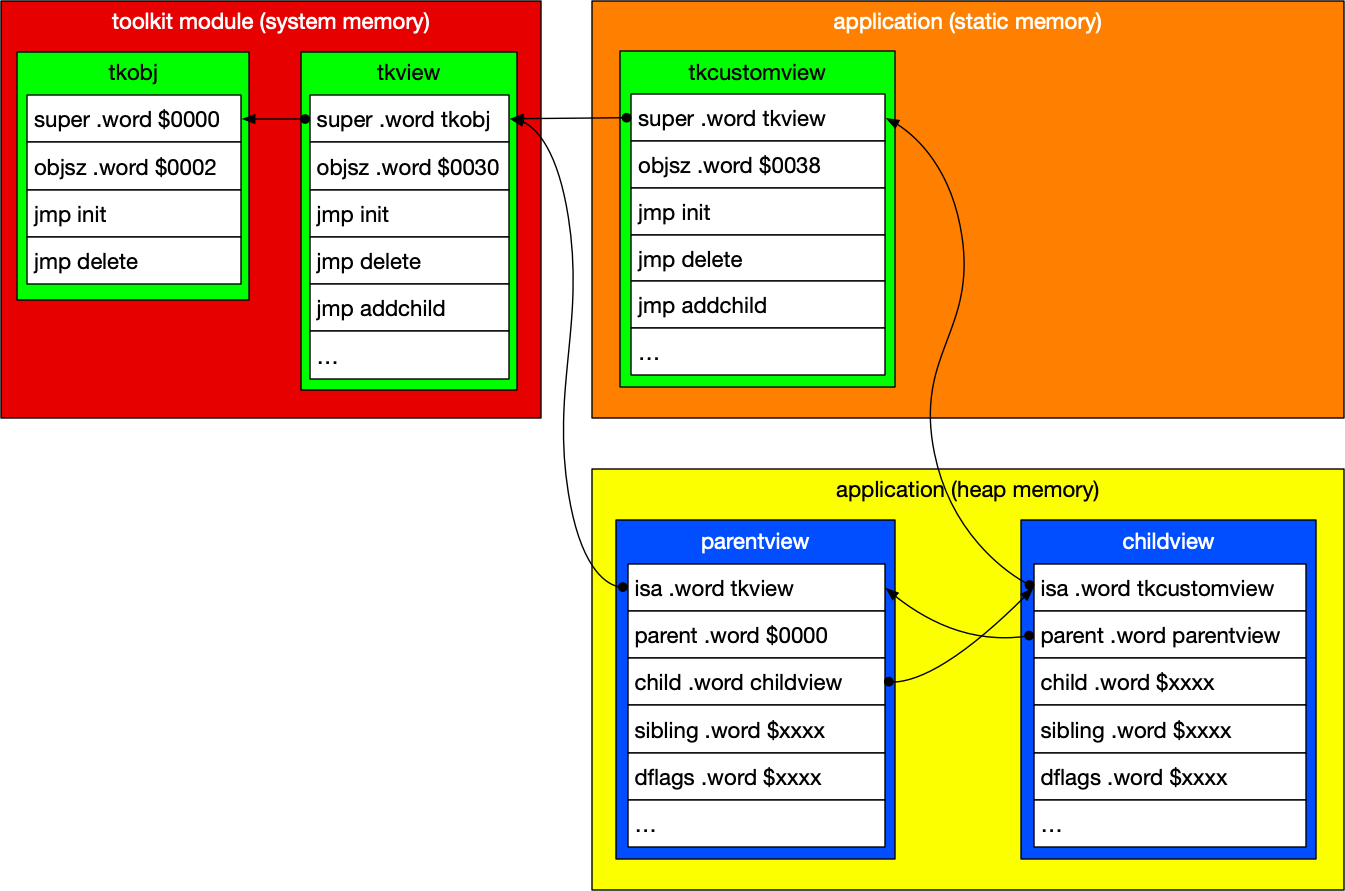
The outer boxes represent general areas of memory. The red box is part of the toolkit module, in system memory. This area, and its contents, are allocated during C64 OS's boot process, when the system modules are loaded in. The orange box is application static memory. This area is allocated when an application is launched. The custom class (tkcustomview) is implemented by the application. The yellow box is heap memory. This is the memory that is initially free when the application is launched. But the application requests a chunk for itself, which is sets aside as the memory pool out of which to make its allocations. As the application runs, it creates instances of the classes, and those objects are allocated upon request from the application's heap memory pool.
There are three classes represented here. Two are built into the toolkit module, tkobj and tkview. Each consists of the two 16-bit words, followed by a jump table. Tkobj's super pointer is $0000 (null), because it's the root object. Tkview's super pointer points to the start of tkobj. Technically the start of tkobj is the memory address where tkobj's own super pointer resides. The third class is provided by the application. In order for the application's custom class to inherit from a toolkit class, its super pointer must be set to point to the class it inherits from. In the diagram, it points to tkview. This connection has to be established at application runtime, usually by the application's init routine. This address cannot simply be hardcoded, but must be looked up at runtime, because the application can run on different versions of C64 OS, and the exact address of tkview will almost certainly change between versions.
In application heap memory, we have two toolkit view objects represented. They are nested together to form part of the UI of the application. Their nesting and other properties define their visual relationship on screen, and also the path which mouse events will travel during hittesting and event processing. The first object (labeled parentview) is an instance of tkview. Note that its first property is the ISA pointer, which points to tkview. Parentview has many other properties. Parent, child and sibling pointers for node relationships are defined by the tkview class. (Note, the diagram is for illustration purposes, the actual layout of the properties is different, and there are many many more.) The parentview's parent pointer is null, because this object is the root of the view hierarchy.
Parentview's child pointer points to another view object. And that view object's parent property points back to parentview. The childview's ISA pointer points to tkcustomview. So, childview is an instance of tkcustomview. This is a small sample of what the hierarchy of a chunk of UI might look like, and the pointers that link all of these entities together.
THIS, CLASS, and how objects call their methods
So far we have discussed how the objects and classes are structured in memory. Subclasses point to their super class, forming an inheritance chain. View objects point to their parent views, first child and sibling views, forming a hierarchical node tree. Each object also has its ISA property that points to its class, thereby identifying what kind of object it is.
The question is now, how do these pointers work? How are they used in 6502 code to implement the behavior of objects and classes?
From a variable pointing to an object, we want to be able to call one of that object's methods. In our assembly code we need an address for the method to JSR to. We can visually follow the links of pointers easily enough. myObject → isa → methodOffset. But how do we actually jump there?
This is where the sophistication of the CPU architecture comes into play. Imagine if we were CPU architects, designing a CPU to be optimized for our software. If we knew that a very common workflow would be to jump through an offset into a jump table that was pointed at by the first two bytes of a structure pointed to by another pointer… we could in theory just build that into the CPU directly. There could be a special JSR mode designed to do method calls given a pointer. And where would that pointer be? Well, perhaps in a special purpose CPU register, which could then double as the reference for the THIS context within the method code.
But we can't do that. So we have to unpack the stages a bit for the 6502. We need to look up the method address, but once the method's code is running, the code needs some reference back to the object. It must be a generic reference, so that all method implementations can always use a standard and generic means of accessing the calling object's properties. As you'll recall, the 6502 has only one addressing mode suitable for looking up offsets through a pointer. It's the indirect index addressing mode. Thank god this mode exists at least, or we'd have to do even more work.
The pointer for indirect indexed addressing must be in zero page. So, C64 OS reserves 4 bytes in ZP for 2 pointers, which the toolkit header defines as THIS and CLASS. The first step is to copy a pointer to an object from main memory into the THIS pointer. Via that pointer the ISA property can be read. The next step is to copy the ISA property into the CLASS pointer. From the CLASS pointer, then, we can use a label for the offset into its jump table for the desired method, and JSR to it. Wait, not so fast, remember, the 6502 does not support indirect indexed with the JSR instruction. Instead, C64 OS reserves 3 more bytes of workspace memory for a JMP instruction plus its two byte address. The next step then is to use indirect indexed LDAs to read the address of the routine and write it into this method redirect vector.
Finally, we can do a JSR to the start address of the method redirect, which will jump us into the method's code. A couple of notes before we get into the method's code. First, BASIC uses a similar technique. In the Commodore Inner Space Anthology the addresses are labelled as "Jump Vector for Functions." For consistency's sake, C64 OS uses the same addresses for its method redirect: $54—$56. Second, we are still passing parameters primarily via registers, because it's so much faster than via the stack or other means. If we were able to do an indirect indexed JSR, it would require the Y register to be the index. This would make it impossible to use Y to pass data. There are already so few registers for passing data that this would be an undesirable limitation. Once we configure the method redirect vector, we can then set all of the registers for passing data to the method, and finally do a JSR through the redirect.
This will work, but it sounds like a big pain in the ass. To make things easier, toolkit has a few more helper routines. One is ptrthis. It takes a RegPtr to an object, and writes the pointer to THIS. Then, it falls through to another helper routine, setclass. Setclass reads the ISA pointer from THIS and copies it to CLASS. So, now, with one call, we can configure both THIS and CLASS. One more helper routine, getmethod takes an offset to a method, looks it up via the CLASS pointer and writes it into the method redirect vector. Thus, to call a class method would look like the following:
Now that actually looks fairly reasonable. Use a macro to grab a RegPtr from a local variable, and call ptrthis to set THIS and CLASS. Load the offset to the method to be called into Y and call getmethod. Boom, everything is configured and ready to go. We can then set the other registers as input parameters depending on what the method takes. In this case using a macro to grab a RegPtr to another object from another local variable. Then just JSR to sysjmp and the method is called.
Once the method code is running, it needs to be able to operate on properties from the calling object. Well that's now easy. The THIS pointer in zero page already points to the object. Method code can easily use indirect indexing to read properties from the object, like this:
Inheritance and Superclass Methods
Object oriented programming is not a panacea, but it has a few advantages over procedural designs. One powerful feature is inheritance. Some core classes already do a lot of important work. TKView, for example, has support for multiple children, it can do hittesting, it can pass events up the view hierarchy, and more. But then comes along another view that is more specialized than TKView, but builds off of it. Something like TKSplit manages two child views, organizes how they are laid out (side-by-side, or one above the other) and adds a bit of event handling to let the user move the split position. It's a small extension of TKView, most of TKView doesn't need to be reimplemented and shouldn't be.
Let's say TKSplit wants to make sure that there are never more than two child views added to it. It will implement its own addchild method. Each time addchild is called it will count the number of children it already has. If it already has two, it can raise an exception, because it can't manage any more. But, if it doesn't yet have two children, it can pass off control to TKView's implementation of addchild to manipulate the node pointers. When TKView's implementation is finished, TKSplit will then do a bit more of its own work to override the position and the resize mask of the child.
How shall it pass off work to TKView? Recall that while a method is executing both the THIS pointer and the CLASS pointer are set. CLASS should be pointed at the class that defines this very method. So for this method to call its superclass's version of itself it must lookup the address of that method, and then jump through it. We're now in a situation very similar to what we were in earlier. If the CPU were more sophisticated this is another instance where we could jump through the superclass pointer to an offset into its jump table. But, no such luck on the 6502.
It must be broken down into several steps again. First, we want to read the superclass pointer by indirect indexed addressing through the CLASS pointer. Then we need to write that address back to the CLASS pointer. Next, we can lookup the method offset through that new CLASS pointer and write it to the method redirect vector. And finally, configure any registers to pass as data and JSR through the method redirect.
Now, why do we overwrite the CLASS pointer? There is a strange side effect of this. The CLASS pointer is no longer the same as the ISA property from the THIS object. The THIS object's ISA points to TKSplit, but CLASS now points to TKView. It's actually very important that we do this, because we do not (in principle) know how our superclass implements its version of this method. Suppose TKView's implementation wanted to call its superclass's implementation. How would it do that? It would reference the superclass pointer from the current CLASS pointer. If we didn't overwrite CLASS with TKView, then TKView's implementation wouldn't get a reference to its own superclass, it would get a reference to itself!! That would be very bad. It would produce a recursive infinite loop that would overflow the stack and crash instantly.
Calling the superclass method, then, overwrites the CLASS pointer. It must, therefore, get restored after the call. Toolkit provides another convenience routine, setsuper. Setsuper replaces CLASS with CLASS → superclass. Then we can make another call to getmethod, passing the method offset in Y, that will fetch the superclass's version of the method and put it into the method redirect. Toolkit also provides a convenient macro, supermethod, to do both calls in one step. Just as before, you can now load up the registers to pass as arguments, and JSR to sysjmp. Immediately after, if you have any more work to do, you must restore the CLASS pointer. This can be restored directly to the memory address of the class that this method knows it belongs to, say, to TKSplit in this case.
Here's how the whole process looks in code:
Faster JMPs and Strange Links
It takes a bit of mental gymnastics to wrap my head around exactly where execution will flow given the complex connections between classes and superclasses, especially when you throw in the node hierarchy and one class's superclass method calling another class's method. It can be a bit of a head spinner. There are a few shortcuts we can take for efficiency's sake, but there are a few gotchas we should talk about too.
The system provides about 14 classes, for starters. All of these classes are assembled in the presence of each other's source code, for a given build of the OS. Additionally, an application may provide some custom classes. Custom classes extend the built-in ones by subclassing them. And those custom classes are assembled together, in the presence of each other's source code. Sometimes custom classes need to make calls into the system classes, these are external calls. But custom classes also make internal calls, calls to methods on other custom classes. Just as the system classes make calls to each other that are internal to the system.
Internal calls can be made more efficient than external calls by skipping the lookup and the redirection. For example, TKSplit knows that it inherits from TKView, and it also knows where TKView is in memory. Even if in a future version of C64 OS TKView changes its place in memory, TKSplit gets updated too, and still knows where TKView is. So, TKSplit can call TKView's version of addchild by jumping directly to the absolute start address of TKView plus the method offset. It must still update the CLASS pointer though. Here's how this would look:
You can see that we no longer need to call supermethod, which means the method offset doesn't need to be loaded into the Y register first. And the address doesn't need to be copied to the method redirect vector. And we don't need to jump through a redirect. The only thing we need to do is manually update CLASS to point to the superclass. This can be done in one line with the #copy16 macro. Our JSR jumps to the absolute address of the jump table entry for addchild provided by TKView.
Some GotchasThis seems pretty cool, it makes you wonder, well, where else could we take some shortcuts? You can take this shortcut in your own classes of course, for the same reason it works internal to the system classes. However, there is another situation that is kind of odd that you have to watch out for. I call these, strange links.
Methods of classes are divided into two broad categories, primary and secondary. A primary method is one which acts directly upon the object's properties. On a machine like the Commodore 64 it may well be that most methods are primary, while on bigger computers with more memory most methods may in fact be secondary. But at least some C64 OS class methods will end up being secondary. A secondary method obtains its data by calling other methods on itself.6
Let's say you've implemented a class, and it has a bunch of methods, some primary some secondary. The implementations, of these methods belonging to one class, are naturally together in the same source code file. Each routine has a label and there is a jump table at the top of the source for other classes to call. In your implementation of a secondary method you need to call another method on this object. But the implementation of the other method is right there! You can see it with your eyeballs, and it has a handy label and everything. All you have to do is JSR to that label. That would be very efficient, right?
The problem is the current method that's executing may have been called as the superclass version of some object that is the subclass of this class. In other words, when your method is executing it could be that CLASS is the same as THIS → ISA, but it could also be that CLASS is different than THIS → ISA. And if it's different, then it is a mistake to simply JSR to that convenient label elsewhere in this source code file. Because what should happen is that your method should call the version of that method implemented by the class that THIS belongs to. And if that's a subclass, well, then you should be calling that subclass's method first. It may be the case that that subclass eventually calls its superclass's version of the method, which is the routine you so conveniently see, but it could just as easily be that the subclass has a totally different way of handling the data.
That is about as head spinning as this gets. It's the only real gotcha that I've run into while working through how the connections work. The bottom line is, if the implementation of a method wants to call another method on the same class, it must do so by calling the version implemented by THIS → ISA. Calling this method is very much like calling a superclass method. First, set CLASS from the THIS → ISA pointer by calling setclass. Then lookup the method and copy to the method redirect with getmethod. JSR to the method redirect, and afterwards, restore CLASS to this method's own class. Just as there is a convenient macro called supermethod, there is also a macro called thismethod that does both steps. It would look like this:
Helpful Toolkit Routines
There are a few routines in the toolkit module that are helpful for working with objects. To conclude this post, I want to discuss just one of them. A few of the others relate to the how views are assembled together in a parent-child hierarchy. I'll save those for the upcoming post that delves into the toolkit classes themselves and what they can do.
instanceofThere are times when it is necessary to know whether a given object is an instance of some class. For example, perhaps you want to know if a class inherits from TKView. Why would you want to know that? Because if it inherits from TKView, you know you can call a method on it that TKView supports, even if what you have is something else, like a TKButton.
You can test if an object "is a" class by comparing a known class pointer to the ISA pointer. But if they don't match that doesn't tell you whether this class inherits from the one you care about. To determine this, you must follow the chain of superclass pointers. THIS → ISA → superclass → superclass → null. Compare each superclass until you find a match, or if you find a null superclass pointer, then you know it doesn't inherit from the comparison class.
This work is done for you by instanceof.
Final thoughts
This time around I think I've nailed how classes actually work. The critical move was separating the object structure from the class structure. Giving objects an ISA pointer, and giving each class structure a superclass pointer. Once that was figured out, having separate zero page pointers for THIS and CLASS followed soon after. But, they make sense for allowing a method to generically call the same method on its superclass, and for that method to be able to invoke a method from its own superclass, and so on.
Although the 6502 was designed in the mid 70's, and the earliest object oriented programming concepts were developed in the 60's, the 6502 was not designed to work with object oriented code. On a CPU designed with OOP in mind, the CPU could have registers designed to function as the THIS and CLASS pointers, and methods and properties could be looked up by indexing off these registers. These pointers could be pushed and pulled to and from the stack automatically upon calling a method on another object, and so on. These are things the 6502 just can't do. But, that doesn't mean it's impossible to program with object oriented patterns. We just need to make careful use of zero page, and use a handful of macros and helper routines to keep us on track.
The next post about Toolkit will delve into the class hierarchy, and how those classes are used together to build a responsive UI.
- It's not quite that extreme. The 6502 actually is useful, and continues to be commercially used today, in embedded systems. [↩]
- I jest. But, just barely. [↩]
- Unless you write directly into stack memory and manipulate the stack pointer manually. [↩]
- There is a bit of complication regarding exactly what address is put on the stack, and in what order. And then a bit more complication about the order they're pulled from the stack and incremented before being put back on the PC. But this is the general process. [↩]
- This, by the way, is a form of self-modifying code. It's powerful, but you can't use it if your code is in ROM. [↩]
- Think about getters and setters. They get and set individual properties. Most other methods access the object's data via the getter and setter methods. [↩]
Do you like what you see?
You've just read one of my high-quality, long-form, weblog posts, for free! First, thank you for your interest, it makes producing this content feel worthwhile. I love to hear your input and feedback in the forums below. And I do my best to answer every question.
I'm creating C64 OS and documenting my progress along the way, to give something to you and contribute to the Commodore community. Please consider purchasing one of the items I am currently offering or making a small donation, to help me continue to bring you updates, in-depth technical discussions and programming reference. Your generous support is greatly appreciated.
Greg Naçu — C64OS.com


