
NEWS, EDITORIALS, REFERENCE
Directory Library, Natural Sorting
Every so often I like to really get into the weeds on some 6502 programming. I have recently been working with the C64 OS directory library that I wrote, as I work on the File Manager homebase application.
The directory library is assembled in two versions, a low memory and a high memory version. These can be dynamically linked into your C64 OS programs. The low memory one is designed to fit into an application binary's memory space, directly following the standard application jump table. The high memory version fits into the memory space of a utility, right after its standard jump table. Since the first code in the directory library is its own jump table, this means that your app or utility's standard jump table is extended to include the directory library's calls.
The directory library is not part of the KERNAL because it takes up at least a couple of pages of code, and only those applications and or utilities that need to work with directories will make use of it.
The point of the directory library is to make it easy to read in a directory from a storage device, and convert it into a consistent structure in memory that can be searched or displayed by your app. Calls to the directory library take a pointer to a configuration structure, and then to a C64 OS File Reference. The configuration allows the directory to be filtered by file type or filename pattern, which are features that it abstracts from the underlying DOS.
Directory data is loaded into memory that is dynamically allocated by the library making calls to the C64 OS KERNAL. A pointer to the directory and its chain of contents are written back to the configuration structure. This allows the library to work with more than one directory loaded in at a time. Your application can decide when it wants the library to deallocate an old directory structure and read in a new one, or it can set one aside and work with a new directory without deallocating the old one, so you can switch back and forth between more than one directory in memory.
When a directory is in memory, the library can be instructed to sort it, by one of four criteria.
- file type
- file size
- filename
- date/time stamp*
Sorting by file type or size automatically sub-sorts by filename. Once a directory is sorted there is a library call to retrieve a pointer to a directory entry by its index, making it easy to display a list of entries that you can scroll up and down through.
Sorting by name has a few configurable options. Case sensitivity can be turned on or off. ASCII to PETSCII translation can be turned on or off (GEOS/Wheels filenames are actually in ASCII, not PETSCII.) And lastly, but certainly not least, natural sorting can be turned on or off. We'll dig into this shortly.
I wrote a blog post about sorting in 6502 code generally, Sorting Algorithms: QuickSort6502. At that time, I hadn't yet built out the directory library. I wasn't sure how the quicksort6502 algorithm would get embedded into an application. But, now I have that quite well worked out. The quicksort6502 routine outlined in the above post is fully in use, but it's nicely abstracted inside the directory library, so you never have to worry about its guts.
Sorting Recap
To very briefly recap, the quicksort6502 routine does not sort arbitrarily large chunks of data by rearranging them in memory. That would be much too slow. Instead, it rearranges a set of upto 256 16-bit pointers. Your directory can be longer than 256 items, but only the first 256 items get sorted.
This may seem like an unfortunate limitation, but there are at least 2 reasons for it. The first is that it is much faster and easier to sort only 256 items than it would be to sort more. The reason is because the high and low byte pointers are stored in two pages, and together they only need a single 8-bit index. The second reason is because of memory constraints generally. A single directory entry is 32-bytes. That means one page of memory can hold 8 directory entries. And to hold a full directory of 256 entries you need 32 pages of memory. You need two additional pages to hold the sorted pointers to all these entries. The File Manager is set up to have 4 tabs, and under each tab can be loaded a different directory. There is not enough total memory for all 4 tabs to have even 256 entries each.

Sourcing a 16-bit pointer from two pages using an 8-bit index.
In fact the File Manager keeps track of the order in which you last accessed the tabs, and if it needs more memory to load in the directory in the tab currently in focus, it will automatically expunge the memory being used by the tab you accessed least recently.
To save additional memory, the 2 pages used to store the sorted pointers to the directory entries are shared by all the directories. This means that when you change tabs, the sorted pointers for the previous tab get expunged, and the directory managed by the new tab gets re-sorted, repopulating the table of pointers. The good news is, the sorting happens very very quickly, like around 1 second for a directory with over 200 entries, even with all the bells and whistles turned on.
The sort routine must be configured with a comparator. The sort routine sets two zero page pointers to two directory entries to be compared, then calls the comparator. The comparator can do anything it wants. It can be arbitrarily complex, as along as it is consistent. Consistent means that if given the same two pointers more than once, the order that it ranks them in must always be the same. The comparator returns its sort recommendation in the carry. The direct result of a CMP instruction is a valid result from a comparator routine as a whole.
Before the sort can begin, it must be configured. The comparator to use is selected, and the options for the filename sort (or sub-sort) are also specified.
While the sort routine performs its work, it repeatedly calls the comparator on pairs of pointers that have been preloaded into zero page addresses. Each pointer is to a directory entry structure. If the comparator is for file size, for example, it sets the Y register to the file size index into the directory entry structure, and dereferences the high byte of file size off one of the pointers and compares to the high byte of file size off the second pointer. First it checks the high bytes, if these are same, then it checks the low bytes, if these are the same it branches down to continue the comparison on filename. And so on.
Sorting Strings
Sorting 8-bit integers is super easy, the CPU has an instruction for doing that, CMP. CMP is essentially just a subtraction whose difference is not recorded but the resultant CPU flags are still set. Thus, the accumulator is unmodified, but the zero flag is set if they are identical, and the negative flag indicates positive or negative result otherwise. This is the reason why all sort comparators use a negative value to mean the first element is smaller. Because A-B = <1 whenever A is smaller than B.
Sorting multi-byte integers is nearly as easy, but it has to be done in stages. From most significant byte to least significant byte, for somewhat obvious reasons. If any more significant bytes are unequal, then the less significant bytes are irrelevant. Just as when you compare (in decimal) 25 to 51. You start with the 10s column, the most significant digit, first. Since 5 is greater than 2, it is totally irrelevant what the 1s column holds.
Sorting strings is more complicated. In the simplest case, each character of a string can be interpreted as though it were an 8-bit integer. Why? Because, lo and behold every character is an 8-bit integer. And very conveniently and completely intentionally the letters in ASCII and PETSCII come in numeric order, "a" is numerically smaller than "b". So sorting strings is a simple matter of comparing the first two bytes, and continuing on to the next two bytes until they are not identical. Easy peasy.
String sorting complications
Complication 1There is an immediate gotcha. Not all strings are the same length. C64 OS's strings are structured as C-strings. Which is to say, a zero (or NUL) byte terminates the string. This is not the only way to structure a string, of course. PASCAL strings start with one or more bytes that prefix the character data to specify its length. The C64 KERNAL ROM has another technique, the final character of a string is in upper case. In PETSCII, upper case means that bit 7 is set, or in other words, the numeric value is negative. This can lead to some efficiencies but at the cost that strings are limited to only using lower case letters.
Since a null terminating byte is a zero, if one C-string is shorter than another they will be automatically different even if the beginning of the longer string is identical to the complete short string, and the shorter string will be sorted as smaller, because its zero byte will be smaller than whatever byte is in that position in the longer string. Like this:
This is a string0 This is a string that is a bit longer0 ↑ the value of NULL is less than the value of a space
Of course, two strings could be absolutely identical, including their length. In which case the two null terminating bytes would be equal. You have to check for that before proceeding to compare the bytes that come following the ends of both these strings.
Complication 2We don't have to wait long after the first gotcha to come across the second problem. The second problem relates to case sensitivity. Small letters and capital letters have different numeric values. (In ASCII and in PETSCII, but we'll return to that as the third issue.) In ASCII the capital letters all have smaller numeric value than the small letters. And so the following strings appear in sorted order:
Betty Carol alexa
In some situations this might be okay. But in many situations this will feel like it's broken. It violates our basic expectation that "Alexa" should come first, because in our minds we discount the miscapitalization as a trivial difference that should be ignored. This is easily overcome by converting each character from A to Z to lowercase first, and then comparing them. It's slighly slower, but also, there may be situations where you don't want this converstion to take place. The C64 OS directory library has a configurable option for turning case sensitivity on or off. It's off by default in the File Manager, but it's available in a menu option, so on any given directory, in any given tab, you can toggle case sensitivity on and the directory will re-sort case sensitively.
Complication 3As alluded to above, there is a further complication in the form of ASCII vs. PETSCII. While the PC/Mac world has long ago moved on to Unicode and UTF-8/16 encoding, we on our C64s typically only need to worry about sorting filenames that are in PETSCII.
Devices such as SD2IEC that give us native access to a PC file system (FAT 16/FAT 32), you would think they'd introduce us to ASCII, but in fact SD2IEC (and others like the VICE FS Driver) transparently translate ASCII to PETSCII. If you want all the dirty details on how SD2IEC works with filenames, I recommend reading my earlier post, Understanding SD2IEC Filenaming.
However, as it happens, devices like SD2IEC are not the primary source of an ASCII invasion into our pristine PETSCII haven. But GEOS is. For reasons that, it has been suggested to me, might be because GEOS was an OS not specifically for the C64 but also for other non-Commodore 8-bit computers such as the Apple ][, it may have made better sense to standardize on ASCII. The result is that when you give a file a name in GEOS, you are typing ASCII characters, and ASCII characters are thence written to the disk's directory entry.
If you later drop back down to the READY prompt, use a non-GEOS program or write a BASIC program and save a file, you get filenames in the same directory not only with mixed case, but with mixed character encodings! Why should this matter? Well, in ASCII, upper case A to Z have lower numeric values than lower case a to z. But in PETSCII upper case A to Z have higher numeric values than lower, and the 4 ranges of letters only partially overlap. See Commodore 64 PETSCII Codes and compare it to http://www.asciitable.com.
This kind of thing used to hardly matter, because 1541 disks have a very small capacity. Most likely you'd have some GEOS work disks for GEOS documents and projects, and you wouldn't use those same disks for non-GEOS things, because the disk just didn't have the space. But as soon as you start having storage devices with largish partition sizes, 10+ megabytes, the likelihood goes up a lot that you'd mix GEOS and non-GEOS files in the same partition or even directory.
The C64 OS directory library has an option to turn on ASCII to PETSCII translation. But this is not perfect. If you have a filename in all lower case PETSCII, it is impossible to know if that name was supposed to be in all upper case ASCII. Essentially, this option just maps lower case ASCII from an unused PETSCII block to the ordinary lower case PETSCII block so that ASCII and PETSCII files get sorted normally together, instead of all of the ASCII lower case names getting sorted together above all the PETSCII lower case names. Because, that looks weird, and frankly, it just looks inexplicable and broken.
Natural Sorting
I should have called this complication 4, but its solution is much more involved, and we're going to look at some 6502 code to explain it.
So the next complication is the issue of natural vs. non-natural sorting. For simplicity, let's ignore ASCII vs. PETSCII encoding and pretend everything is in PETSCII. Numbers, the digits 0 to 9 appear in the character set from $30 to $39. These are in order, intentionally, just like the alphabetic characters, and they all come before the lower case letters. So any string containing a number character will sort before a string that has an alphabetic character at that index.
In PETSCII a "1" ($31) is smaller than an "a" ($41), but it's also smaller than a "2" ($32), so any string that contains a "1" at a given index will sort above a string that contains a "2" at that same index (given that the strings are equal up to that point.) At first blush, you'd think, Yeah, well, that makes sense. The problem is when strings of numeric characters occur together, they are assessed one character at a time without consideration for the magnitude of the complete number that that first numeric character may be a part of.
In other words, you end up with a sort order like this:
Photo 110 Photo 12 Photo 25 Photo 276 Photo 28 Photo 3
When you look at this, it looks broken. Just as our mind discounts the miscapitalization of a name, and perceives "alexa" as being the same as "Alexa", we also perceive a string that contains the number "110" as being bigger than a string that contains just the number "3". Obviously, 110 is bigger than 3. And 276 is obviously bigger than 28, and so on. But if the routine only ever looks at and compares one character at a time, all "1"s come before all "3"s because "1" is less than "3" whether it's the start of "1" or "100000".
What our mind wants, what it expects, is that the number segments should come in the order of their full numeric value. Like this:
Photo 3 Photo 12 Photo 25 Photo 28 Photo 110 Photo 276
This just looks much more natural, even though it is more complex to compute. And hence it is referred to as natural sorting.
All modern operating systems do natural sorting and you don't even notice. Although you almost certainly would notice if they did not use natural sorting, the instinct is that strong. But you are still likely to run into this, for example, if you're doing some web-app programming where everything is kinda like the wild west. You have an array and you write your own sort routine, thinking that you're cool, and all of a sudden you realize that natural sorting is a thing you have to know about. This is pretty much what happend to me maybe 10 years ago.
Implementing Natural Sorting
In Javascript, an array object's built-in sort routine does not do natural sorting. Below you can see an example in the Safari web console. I made an array of 6 strings, with the example filenames above. I made one exception, putting "Photo 3" in the middle of the "2"s range, just to be sure the sort actually does something. Let's see the result.

Calling sort rearranges the elements of the array alright, but it's moved "Photo 3" to the end instead of to the beginning. And 276 still falls between 25 and 28. Ergo, this is not doing natural sorting.
If you want to do natural sorting, you have to supply your own comparator, and then implement the natural comparison routine yourself. I hobbled together my own natural sorting comparator a long time ago, but it is seriously not pretty, and it is rather obviously not at all efficient.1 The question is, can natural sorting be implemented painlessly and efficiently in 6502?
The short answer is, yes. But, we're here for the long answer.
The C language is about as close as you can get to the bare metal and still be in a high level language. You can practically compile it in your head. That is to say, it isn't a huge stretch to imagine how your C code will be translated into the equivalent machine code. (Someday I'll write a blog post about why C is so much less efficient than assembly, on the 6502/6510 at least.) But, if you can find an implementation of something in plain C, you can probably translate it manually to 6510 assembly, and then tune it to be more efficient.
I found the following: natsort by sourcefrog on GitHub. It's quite short, only about 150 lines of well formatted and well commented C. What I normally do when porting code from C is to rearrange the code, simplify it where it's obvious to do that and gradually convert it to a sort of pseudo-code that makes the ties and connections to the eventual assembly more obvious. For example, I rename variables to X and Y where I know the X and Y registers will be used, and I use gotos where I think branches will be used. And I get rid of explicitly C verbiage.
Here's my pseudo-code rewrite of the C version of natsort. I'll use it to talk about how the algorithm works generally, and then show and discuss the final 6502 version.
There are two primitive helper functions that come first. isdigit and tolower. These are both very simple. isdigit returns true if the value is from $30 to $39, the PETSCII values for the digits "0" to "9". tolower returns the value unmodified if it's outside the range of "A" to "Z" in PETSCII, otherwise it subtracts $80, which will shift an uppercase alphabetic character to its lowercase equivalent. (Actually, the 6502 implementation of tolower just clears bit 7. This is slightly better because you don't have to worry about how the carry is set for the subtraction.)
Next are a few global variables. Most of these are just static memory addresses. The labels to them will only be globally accessible to the code within the directory library. ci is the current index into the two strings. ca and cb are single characters that will be copied from the strings at position ci and compared to each other. bias will be used when comparing the numeric stretches of the strings, so we'll return to that. And lastly, here, a and b are going to end up as zero page pointers to the strings being compared.
Then we have the cmp_nums function, which will be used to compare numeric stretches, but let's come back to this in a moment. Lastly, we have the main meat and potatoes routine, strnatcasecmp. This is a case insensitive natural compare routine. This routine can be used as the comparator for the quicksort routine. This is going to be called many times over, with a and b pointing to different strings each time, so we need it to be as efficient as possible.
Here's a thing to bear in mind. Comparing two strings that are totally different is extremely fast. If the first two characters are different, the routine returns after only ever having looked at the first two characters. The slowest or least efficient case would be if the strings were long and identical or nearly identical, with stretches of digits intermixed with stretches of non-digits.
Breakdown
So let's break this down. Reset the index to 0, and note the loop label. Grab one character from each string at the current index, and increment the index in preparation for the next interation of the loop.
Now we have to check if both characters are digits. If either one is not a digit, they can just be compared as usual. A single digit will sort below an alphabetic character, but above many of the punctuation and other symbols. So, if they're not both digits, we check to see if they're both null. If they're both null, we've reached the ends of the strings without finding any difference, these strings are equal and the comparator returns 0.
Continuing on, since one or both of them is a non-digit, we run both of them through the tolower routine. If one of them was "z" and the other was "Z" now they'll both be "z". If these two characters are equal, branch to the loop label to continue by comparing the next two characters. If they're not equal, the act of comparing them will have set the CPU's negative flag accordingly and the comparator can simply return.
And there you have it. In the case where the strings never have two digits found at the same index, this routine will work out just fine and there is nothing more to it.
But what happens if there are two digits found at the same index? Let's say we pull a character at the current index from both strings, we check and lo and behold, both are digits. The naive thing to do is to, say, see that one of them is "9" and the other "1" and conclude "9" is bigger than "1". Because of course "9" could be the start of a stretch of digits "92" and "1" could be the start of a stretch of digits "1024". And if this were the case, clearly we would want the string where the "1" is found first to ultimately sort higher.
As soon as any two digits are found at the same index, we will enter a subroutine for comparing numeric stretches. But first, we clear the bias.
The bias is essential to how this works. When we start comparing two stretches of digits, we have no idea whether their lengths will match. If their lengths end up matching, then, we've been comparing the same column values all along. And if that's the case, we want to know which most-significant-digit was greater. The bias records the comparison result of the first two digits encountered that differ.
But if it turns out their lengths don't match, then we haven't even been comparing matching column values. Whichever numeric string is longer, its first digit is in a higher place column than the shorter number even has. And ergo the longer number is bigger irrespective of the bias. If the numeric strings are the same length, though, the bias is returned. If the numbers are both the same length, and also the same value, the bias remains 0 after each new pair of digits is compared.
Imperfect, ambiguous, and the nature of compromise
Sometimes as I'm writing these posts I question myself, is it really necessary for me to go into this sort of detail? But the truth is that these posts are just me thinking out loud. They are partially for whoever might stumble on them and find them useful, but they are mostly for me to work through my own thoughts.
As I was writing the above, it struck me. Wait a second, something doesn't make sense. What happens if the number has leading zeros?
0094 0102
In the above example, both have leading zeros. But the first has two leading zeros and the second has only one. Nonetheless they are the same length, four characters. Comparing at index 0 gives a bias of zero. Comparing at index 1, gives a bias to the second because 1 > 0. Comparing 9 to 0 makes no difference because the bias is already set. And comparing 4 to 2 makes no difference because the bias is already set. Then both substrings end and the the bias is returned.
Huh. That actually works out! 0102 is indeed bigger than 0094 after all.
Hold on. What happens if they have leading zeros, and they are not the same length?
00094 0102
These should resolve the same as above, but they don't. As soon as the routine notices that 0102 is shorter than 00094 it returns that 00094 is the bigger value. And that's not right. I checked on my C128 with some sample file names, and sure enough this "bug" exists. Damn.
So that means we should be ignoring leading zeros, right? But hold on, that's not quite right either. What happens if the value with the leading zeros is part of a decimal segment? In that case the leading zeros are relevant.
0.000941 0.0102
Following that decimal point, if you ignored all the zeros, you'd compare 941 to 102, and 941 would be bigger. But 0.01 is in fact much bigger than 0.0009. Right, so that means we actually need to be even more sophisticated and check for a decimal point? Uh-oh. If you think about it for 10 seconds more, there is a new problem. What if the number has multiple points as in an IP address, or a stylized phone number, or multi-point version numbers.
800.778.0015 800.778.005
Which of these should be bigger? I went back to the source C code by sourcefrog to see how Martin Pool was handling this.
Leading zeros are not ignored, which tends to give more reasonable results on decimal fractions. Martin Pool — SourceFrog — https://github.com/sourcefrog/natsort/
His routine does not check for a decimal place. It does not remove leading zeros. But he has two comparison routines depending on whether one or both of the numbers begins with a leading zero. But the crucial point is that, in his opinion, it tends to give more reasonable results. The more perfectly you try to solve this problem, the more the computational cost rises, and yet in the end, some situations are still ambiguous. Two perfectly reasonable human beings asked to sort a list of strings might end up sorting them differently.
As a final test of my sanity, I did some experimentation with filename sorting in the macOS Finder. After some amount of playing, I stumbled upon this little gem.
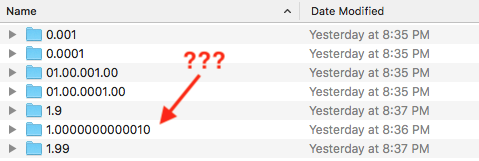
macOS Finder natural sorting error
Now, correct me if I'm wrong, but 1.0000000000010 should be much smaller than either 1.9 or 1.99 and yet, somehow it gets sorted between 1.9 and 1.99. I draw two important conclusions from this. The first is that, even a modern Mac, running a recent version of a modern commercial OS, with gigabytes of RAM and GHz of multicore CPU action, does not get this right.
The second conclusion I draw is this: I've been using a Mac since before the release of Mac OS X almost 20 years ago. And in all that time, I have never noticed that this problem exists. I only uncovered it now, because I was digging deep and trying hard to find issues like this. I also did a whole bunch of tests on my C128, and I never organically stumbled upon this issue. It only occurred to me because I was being so careful here, trying to describe how it works.
What this means is that, in the end, there are some situations in which the natural sort routine in the C64 OS directory library will sort wrong. But, for its simplicity and speed, and for the number of cases it covers well, I'm just going to leave it as it is. Which is what we're going look at below.
6502 Implementation of Natural Sort
Finally, let's check out a 6502 implementation of the above pseudo-code.
Alrighty, let's dig in.
(NOTE: Upon rereading this, I realize the source code isn't visible while reading the descriptive breakdown below. You may find it useful to open this post in two windows, so you can see the source code at the same time as reading about it.)
First thing to point out. The static variables come at the top. detmp and depiv are our zero page pointers to the directory entries to be sorted. These are populated by the quicksort routine. That de prefix comes from "Directory Entry", and piv comes from the "pivot" used by the quicksort algorithm.
ca and cb are single characters extracted for comparison from the two strings being compared. And bias will be used in the natural sort comparator.
The first routine we have is confcmp, lines 12 to 53. Before performing a sort the parameters have to be configured. The index of the sort comparator to use is passed in the X register. Below the routine is a table of sort fields to comparator routines.
| Index | Sort Field |
|---|---|
| 0 | disk order |
| 1 | filename |
| 2 | file size |
| 3 | file type |
| 4 | date/time stamp * |
Disk order is an exception, but we'll return to this. Regardless of which other sort field you choose, file size, file type, or date/time stamp, if two files have the same size, type or stamp, it will fall through to subsort on their filenames. For this reason, it is necessary to specify the parameters for the filename string-based sort even if you specify the file type as the sort comparator. Those parameters are passed in the accumulator.
The string-sort parameters are case insensitive and ASCII to PETSCII translation. These are passed in bits 7 and 6 of the accumulator, because the BIT instruction makes it very easy to test these bits.
Let's talk about the BIT instruction for a minute. It's kind of an odd duck. BIT logically ANDs the contents of the accumulator and a memory address, the result of which only affects the Zero flag. I'm not using BIT for this purpose, though. Additionally, the Negative flag is set to the value of bit 7, and the oVerflow flag is set to the value of bit 6 of the contents of the memory address, regardless of what's in the accumulator. Note, we're passing our parameters in the accumulator, but BIT pulls the negative and overflow flags from a byte in memory. So, the first thing we do is write the accumulator to a temporary address, and immediately test that address with BIT. I'm using the same zero page address that will later be used for bias. This will not cause a problem, because bias gets cleared explicitly every time a numeric segment of a string is encountered.
There is another common use for BIT that is not be immediately obvious. Because it affects flags but doesn't affect any registers, it has relatively few side effects. For this reason, it can be used to force the CPU to skip either one or two bytes, depending on whether you use the zero page or absolute address version of it. For example, the following is found in the C64's KERNAL ROM:
.,F6FB A9 01 LDA #$01 'too many files' error .:F6FD 2C .BYTE $2C .,F6FE A9 02 LDA #$02 'file already open' error .:F700 2C .BYTE $2C .,F701 A9 03 LDA #$03 'file not open' error .:F703 2C .BYTE $2C .,F704 A9 04 LDA #$04 'file not found' error .:F706 2C .BYTE $2C .,F707 A9 05 LDA #$05 'device not present' error .:F709 2C .BYTE $2C .,F70A A9 06 LDA #$06 'not input file' error .:F70C 2C .BYTE $2C .,F70D A9 07 LDA #$07 'not output file' error .:F70F 2C .BYTE $2C .,F710 A9 08 LDA #$08 'missing file name' error .:F712 2C .BYTE $2C .,F713 A9 09 LDA #$09 'illegal device number' error
The first time I saw this, I thought, what the devil is going on here? To initiate a too many files error, KERNAL code can JMP $F6FB. That sets the accumulator to $01. The CPU then interprets the following byte as code. $2C is the op-code for absolute BIT, it executes the BIT, which causes the following two bytes to be interpreted as its argument data. In other words, the following LDA #$02 doesn't get executed, because those bytes are read in as the absolute address for the BIT instruction. But then that leads the CPU to the next .BYTE $2C which is another BIT instruction. This interleaving pattern has the effect of falling through all the other LDAs. At the end of the cascade, the accumulator still contains $01.
I take the time to point this out, because the sorting code we're about to look at will use this trick, so we may as well know how it works.
So we BIT the sort parameters byte. This configures the Negative and the oVerflow flags. Now, there are lots of things that change the negative flag, so you have to use its state right away. Otherwise, the moment you load any register the negative flag will be modified and you'll lose its result from the BIT. The oVerflow flag on the other hand is much more stable. There are very few instructions that affect it. The main ones are ADC and SBC. Other than those, it only gets affected in rather arcane ways. PLP pulls the entire processor status byte from the stack. RTI is similar, the status byte is pushed to the stack automatically when an interrupt occurs. RTI restores the status byte at the end of the interrupt. There is also the CLV instruction, this is used to explicitly clear the oVerflow flag. And the only other instruction that affects it is BIT, which we're using here. So we can do some work as a result of the N flag and let the V flag hang out and still retain its state.
Thus, line 18, BPL is branch if positive, aka the negative flag is low. I'm using counted offsets for these branches because I find the use of momentary labels to be a bit noisy, and because Turbo Macro Pro (the native C64 version) limits the number of labels you can use in a single source file. The *+14 will branch past the Configure Case Insensitive to the Configure Case Sensitive. But both cases are structured very similarly, so let's just see what they do. To turn case sensitivity off, 15 is written to cmpnext+3 and 11 is written to cmpnext+7. To turn case sensitivity on, 7 is written to cmpnext+3 and 3 is written to cmpnext+7.
Although at first sight this is a bit confusing, I think it's clever. Here's how it works. cmpnext is a label at that part of the code that is equivalent to the check to see if both ca and cb are equal to zero. Doing multiple logical comparisons such as if(ca == 0 && cb == 0), in assembly, requires breaking down each step as a separate instruction. If they are both zero, then we'll do something. Therefore, we check ca and if it's not zero we branch past everything else and carry on. Otherwise, we check cb and if it's not zero we branch past everything else and carry on. Ergo, only if both are zero will it fail to branch and get to the conditional code. That conditional code then returns, and therefore never falls through.
Assuming one or both is not zero, that is, assuming the conditional code is skipped, the very next thing to do is convert both to lower case. But only if case sensitivity is turned off. If case sensitivity is on, we'll want to skip over the case conversion. So, after confirming that at least one of the values is not zero, and skipping over the conditional return, we should now check to see if case sensitivity is on, and if so we should skip over the case conversion too, right? Yes, but, if case sensitivity is turned on, it's turned on for the entire execution of this sort, which could represent hundreds of calls to the comparator.
Instead of checking to see if it's turned on in every call to the comparator, and then branching in response to that check, we really only need to check once. confcmp, thus, checks to see if case sensitivity is on or off, and it adjusts the branch destination of the zero checks. But here's the thing, those zero checks already have to be made, and they already have to branch, so branching directly to the correct code to handle the case in/sensitivity means there is zero overhead necessary to check for case insensitivity. That is very cool!
Back in the confcmp routine, following the configuration of case in/sensitivity, we use the oVerflow flag to check for ASCII 2 PETSCII conversion. I should note that if case sensitivity is turned on, there is no ASCII 2 PETSCII conversion performed, all bytes are left unmodified. If however, you're going to normalize case, you can opt to also convert ASCII characters to that same normalized PETSCII case. The conversion is off by default.
Here's another trick in the sleeve. The first instruction of the tolower routine (not included in the source above), is a BNE. That BNE branches when the byte passed in is not zero. If it is zero, then it doesn't matter because a zero in ASCII is the same as a zero in PETSCII. But all other characters will get routed just past the conversion routine.
In confcmp though, if you opt to turn ASCII 2 PETSCII conversion on, it replaces the BNE with a $24. This is the op-code for a zero page BIT. The BIT is executed instead of the BNE, and the single byte branch offset is read in as the BIT's single zero page address byte. This does essentially nothing, except prevent the branch and and thus falls through to the ASCII 2 PETSCII conversion code. Very slick. It should now be clear why programming in 6502 is an art. And also why it is possible to make the code more efficient than a compiler typically would.
The last stage of the confcmp is to configure the comparator routine itself. There is a routine called here, presort, that I haven't included as it's out of the scope of this post. I mentioned earlier that the directory library supports multiple directories, but it only maintains a single pair of memory pages for the sorted directory entry pointers for one directory. In other words, you have a chain of directory entry structures in memory, linked together to form one directory, and you have another chain of directory entry structures elsewhere in memory to form a totally different directory. But when you want to list and navigate one of those, you point the directory library at the root entry of that directory and call presort.
Presort follows the chain and adds pointers to each directory entry to the two memory pages ready for those pointers to be sorted. The chain of directory entries in memory is naturally in the order of the files on disk, because, that's the order they get read from disk into memory. The file manager offers a sort option of disk order. Which basically amounts to, not sorted. Obviously, case sensitivity and ASCII conversion have no influence on disk order. So, if you call confcmp with disk order, it calls presort for you and returns. Otherwise, it fetches the high and low bytes of the comparator routine from the table that follows and writes them into the JSR address to the compare routine.
The label compare is not actually shown here. It's part of the quicksort routine. But, needless to say, at some point, quicksort has configured detmp and depiv to two directory entries and it needs to compare them. It will JSR to whatever routine was stuffed into that JSR call by confcmp. This is a minor form of self-modifying code.2
Almost there. Quicksort's turn.
Now that we have configured which comparator routine to use, and some of the optional parameters for the string sorting, we don't make explict calls anymore.
Quicksort begins doing its thing (and you can read about my implementation in Sorting Algorithms: QuickSort6502). Its task is to sort all the pointers that were configured by the presort routine. Each time it calls a comparator routine, detmp and depiv are already set and the comparator merely needs to compare them.
All of the comparators preserve the X and Y registers, and return the comparison result in the carry. The X register is actually never used, so preserving it is easy. The Y register on the other hand is needed by the comparator. To preserve Y, the first thing that each comparator does is writes Y to yout+1, and all the comparators exit via yout. Y is restored from there and then returns.
compare typeLet's start with cmp_type. It's very straightforward, and structurally the same as cmp_size and cmp_date. cmp_type is only comparing a single byte. After backing up the Y register, it sets the Y register to #fdtype, to index the file type off the two pointers. Then it loads the type from detmp, and compares it to the type from depiv. If they're not equal, it branches directly to yout, so it can restore Y and return. The carry has been set by the CMP instruction.
Now let's suppose that the file type of both directory entries is the same, two SEQ files, for example. If they're equal, it branches to cmp_name+3. The +3 skips that comparator's backup of the Y register, since the Y register has already been backed up, and it no longer holds its original value anyway. Otherwise, it just carries on to compare the two directory entries on their filename. We'll come back to this.
compare sizeThe cmp_size comparator is basically the same as cmp_type, except that a file size is 16-bit rather than 8-bit. So it compares the high bytes first, if they're the same it compares the low bytes, and if they're the same it falls through to compare filenames.
compare dateLastly, although unimplemented, cmp_date is just like these others, except that a datetime stamp is 5 bytes. Year, Month, Day, Hour, Minute. They get compared in that order, most significant to least significant. If by some fluke they share exactly the same datetime stamp then it falls through to compare on filename again.
Comparing Filenames, in 6502
We've already been over the principle of how this works in the pseudo-code. Now we're really just getting down to the nitty gritty of how I've implemented it in 6502. If you're following along in the source code, this is now everything from line 99 down to the end.
If cmp_name is called directly from quicksort, the first thing it does is backs up the Y register. Any of the other comparators that fallthrough will skip this. Then we use the Y register to index the first byte of the filename, #fdname. And here begins the cmploop, which is the main loop over each character in the strings.
The very first step is to copy one character from each string into the zero page variables ca and cb and increment the Y index, just as in the pseudo-code. Next we have our check to see if both characters are digits. In assembly, as mentioned earlier, multiple logical operations have to be performed a step at a time. The accumulator already holds the value stashed at cb, so we can just call sstr+isdigit_ which takes its argument in the accumulator. isdigit is part of the C64 OS KERNAL, in the string module.
You may note that doing a JSR sstr+isdigit_ is a direct jump into the C64 OS KERNAL, without doing a KERNAL module lookup. You should never do this in your application, utility or driver code. You should use the #syscall macro (isdigit #syscall lstr, isdigit_) and use the initexterns call to resolve the address of that system call at runtime. If you do not do this, your application will break as soon as the KERNAL is updated in the next version of C64 OS. Why, then, am I doing this in this directory library? Because a core library, included with C64 OS, is neither application, nor utility, nor driver code. Your application or utility dynamically links to the directory library, and so do the included File Manager application and Files utility. But the directory library itself gets reassembled when the KERNAL gets updated.
Making a direct call to the KERNAL is slightly faster and tighter than using the #syscall macro, but it is only safe for core system libraries, or for one KERNAL module calling into another.
If cb is not a digit, we can compare them directly and thus we branch to cmpnext. If it is a digit then we check to see if ca is a digit too. If they aren't both digits we can just branch down to cmpnext. So let's go there before coming back up to explore what happens when they are found to both be digits.
cmpnext, if you'll recall, is where we configured the branch distances to handle case sensitivity. Each character is checked to see if it is null. If both are actually null, then we've reached the end of these strings without finding any difference. This is exceedingly unlikely for filenames, by the way, but it's not impossible, because people do hack directories to produce filenames that are the same, especially for visual separators and such. We simply clear the carry and branch on the cleared carry down to yout, to restore Y and return the comparison result.
Imagining now that either one of these characters is not null, we will be branched either to the code for a case sensitive compare or a case insensitive compare, depending on how we configured the comparator way back in the first call to confcmp. The case sensitive compare is obviously the easier of the two. We load the value from ca and CMP it to cb. If they're different we branch to yout, restore Y and return the result in the carry.
If the result of this single character compare is that they are the same, then we loop back up to cmpnext to continue on to the next character in the strings.
Case insensitive comparison is not particularly harder. The only real gotcha in any of these comparators is that in order for the carry to be set correctly, the arguments have to come in the right order. CMP compares the accumulator to a memory address. The value in the accumulator has to have come from the directory entry detmp and the memory addressed compared against must be the value pulled from depiv. In the case of the string comparison, ca is always from detmp and thus must be in the accumulator (a nice mnemonic that CA must be in A.) while cb is always from depiv.
Thus, to do the tolower conversion, read cb into the accumulator, pump it through tolower (which may also ASCII 2 PETSCII convert it too), and write the result back to cb. Next read ca into the accumulator, pump it through tolower and the result is now in the accumulator ready to be compared against cb. At that point it's the same as the case sensitive compare. If they're different, the comparison is over. But if they're the same, we branch back up to cmpnext to continue on with the next character in the strings.
The very last leg
It's taken us a while to get here, almost 10,000 words, but we are on the very last leg of the journey. What happens when we pull two characters from the two strings, and find that both of them are digits? This happens at line 120. And we've seen it all already in the pseudo-code. Clear the bias, and then hop into the number comparison subroutine cmp_nums.
In the pseudo-code we saw that the very first line of cmp_nums() was a goto checkbias; statement. A limitation of C (a very sensible one, both for sanity but also for technical reasons) makes it impossible for a goto to cross functional scopes. The reason is because every C function is predicated on the assumption that all of its local variables have been properly established on the stack. When the function returns, all of its stack use is subsequently undone. It makes no sense for the CPU to be able to be jumped to the middle of a C function, bypassing all the stack preparatory steps that happen as part of entering the top of the function.3
Assembly code has no such limitations. This can, in certain ways, make it more powerful or more efficient, but at the great risk of creating an unholy mess of spaghetti. A JSR jumps the CPU to any place in memory, and the only preparatory step is pushing the return address to the stack. There is no overarching structure in raw assembly language that firmly delineates the bounds of a single function.
So the first jump into cmp_nums is to the chkbias routine. This immediately works on the first two characters that we've already found in the strings to both be digits. If they're the same, the bias is left at 0, and we loop back up to the top of cmp_nums to fetch the next two characters to see if they too are digits. But if the first two digits are different, the bias is set right away. The bias is set on the first pair of digits that aren't the same. -1 when ca is less than cb. +1 when ca is greater than cb.
The next characters are fetched, and there is some complicated logic. The isdigit routine returns with the carry set if it is a digit, or clear if it is not a digit. The basic idea is to figure out which string is shorter. If cb is a digit, then skip down to check if ca is a digit. If they're both still digits, now we have to worry about the bias. If the bias is already set, then just loop back up to get the next two characters looking for the end of the run of digits. But it could be that the bias is still zero, which is what would happen if all the preceding pairs of digits were the same. In that case, we need to check if these two digits are the same or different. If the bias is not set, but these two digits are different, then the bias will be based upon these digits.
Eventually one of 3 things will happen. 1) ca will no longer contain a digit while cb still does. That will make cb longer, and the bias will be over written with -1 and returned. 2) cb will no longer contain a digit while ca still does. That will make ca longer, and the bias will be overwritten as +1 and returned. Or 3) neither ca nor cb contains a digit in which case the bias will be returned as is. If the bias is 0, that's because all along, every pair of digits has been the same, and the whole overall number string is the same. Or, the bias will indicate which number is bigger based on the most significant place that is different.
After returning the bias, at line 125, if the bias is zero, then we continue analyzing the string for more characters. We could encounter another string of numbers somewhere deeper in the string. But if the bias is either +1 or -1, that gets converted to setting or clearing the carry and returning that comparison result to quicksort.
Final Thoughts
Hopefully someone will find this useful. Not just for natural sorting, but for the fun and curiosity of implementing something in 6502 assembly.
Lastly, I assembled this code into a standalone C64 binary that can be invoked from the READY prompt. It's not suitable for distribution, because it requires me to manually load some of the C64 OS KERNAL modules into memory to make it actually work. But, this at least gives me the ability to navigate around the file system and test it out on various directories containing a wide variety and number of files.
I made a quick video of this, which I tweeted out some while ago. Here it is.
Keep making your beloved C64 do wonderful things! And enjoy the summer.
- Of course there are tons of solutions to find if you look for them. And apparently Javascript already has at least one solution built in, e.g. String.prototype.localeCompare
- A more major form of self-modification is when the instructions themselves are changed and not merely their absolute arguments. Changing that BNE to a BIT is, in my humble opinion, a major form of self-modification.
- See this stack overflow question get shot down.
Do you like what you see?
You've just read one of my high-quality, long-form, weblog posts, for free! First, thank you for your interest, it makes producing this content feel worthwhile. I love to hear your input and feedback in the forums below. And I do my best to answer every question.
I'm creating C64 OS and documenting my progress along the way, to give something to you and contribute to the Commodore community. Please consider purchasing one of the items I am currently offering or making a small donation, to help me continue to bring you updates, in-depth technical discussions and programming reference. Your generous support is greatly appreciated.
Greg Naçu — C64OS.com


